IB
工业基准(IB)是一种强化学习基准环境,旨在模拟各种工业控制任务(如风力或燃气轮机、化学反应器)中呈现的特性。它包括现实工业环境中经常遇到的问题,如高维连续状态和动作空间、延迟奖励、复杂的噪声模式以及多个反应目标的高随机性。我们还扩展了原始的工业基准环境,将系统状态的两个维度添加到观测空间中,以计算每一步的即时奖励。由于工业基准环境本身是一个高维度、高随机性的环境,所以在这个环境上采样数据时,并没有给动作添加显式噪声。
工业基准(IB)是一种强化学习基准环境,旨在模拟各种工业控制任务(如风力或燃气轮机、化学反应器)中呈现的特性。它包括现实工业环境中经常遇到的问题,如高维连续状态和动作空间、延迟奖励、复杂的噪声模式以及多个反应目标的高随机性。我们还扩展了原始的工业基准环境,将系统状态的两个维度添加到观测空间中,以计算每一步的即时奖励。由于工业基准环境本身是一个高维度、高随机性的环境,所以在这个环境上采样数据时,并没有给动作添加显式噪声。
FinRL环境提供了一种建立股票交易模拟器的方法,可以复制真实的股票市场,并提供回测支持,其实施考虑了交易手续费、市场流动性和投资者风险规避等因素。在FinRL环境下,每个交易日可以对股票池中的股票进行一次交易。奖励函数是当天结束时与前一天总资产价值的差额。随着时间的推移,环境存在自我演化。
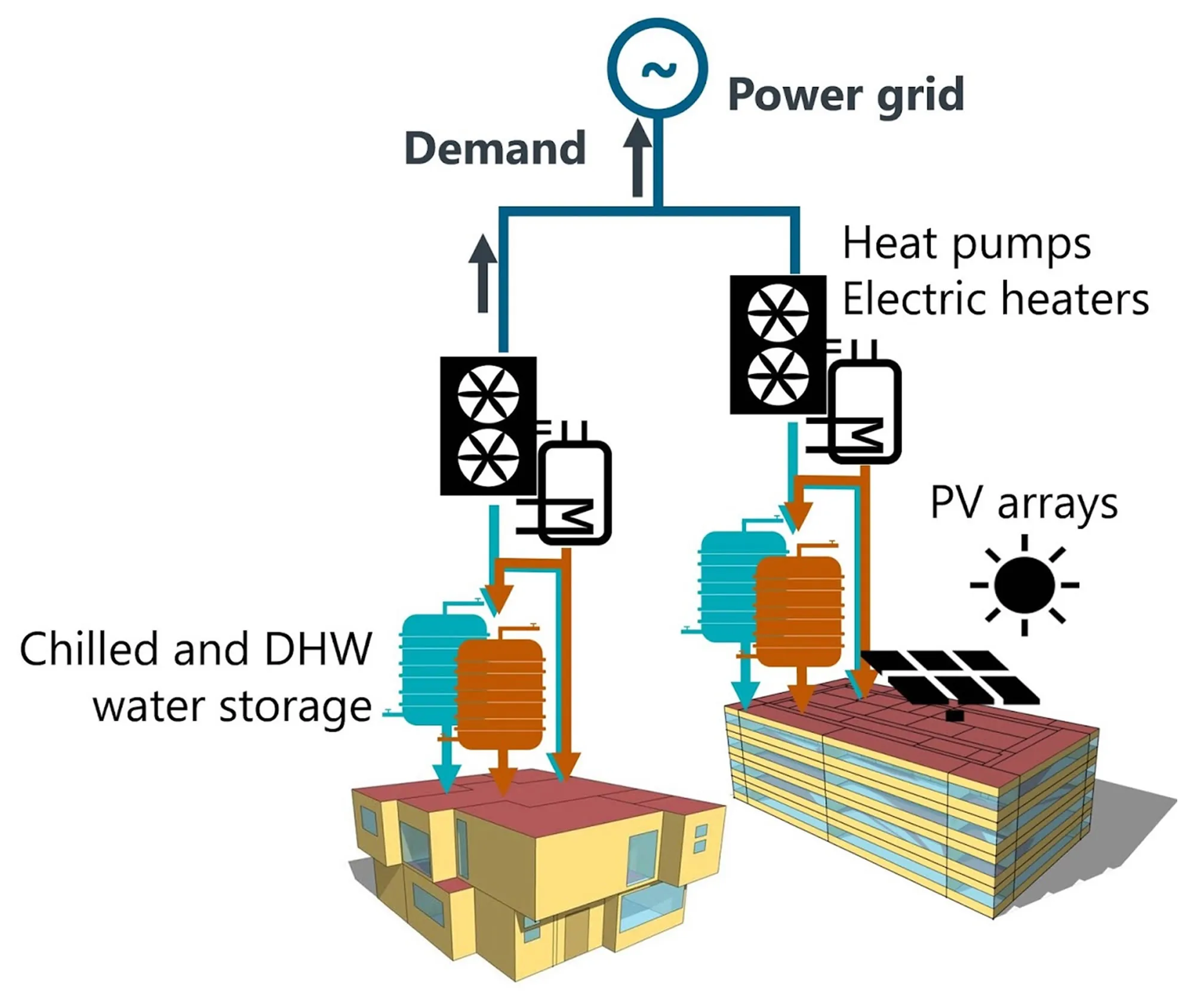
CityLearn(CL)环境是一个类似OpenAIGym的环境,它通过控制不同类型建筑的储能来重塑电力需求的聚集曲线。高电力需求提高了电价和配电网的总体成本。扁平化、平滑化和缩小电力需求曲线有助于降低发电、输电和配电的运营和资本成本。优化的目标是协调用电方(即建筑物)对生活热水和冷水储存的控制,以重塑电力需求的总体曲线。
促销推荐环境模仿了某个真实的促销平台,该平台的运营人员每天会给每个用户发不同的折扣券。折扣券的数量和数值会影响用户的行为。更高的折扣通常会促销,但通常也会增加成本。平台的目标是最大化自己的总收入。该环境的部分组件来自一个真实世界的促销项目。该环境的历史数据中,历史动作由真实运营人员产生。
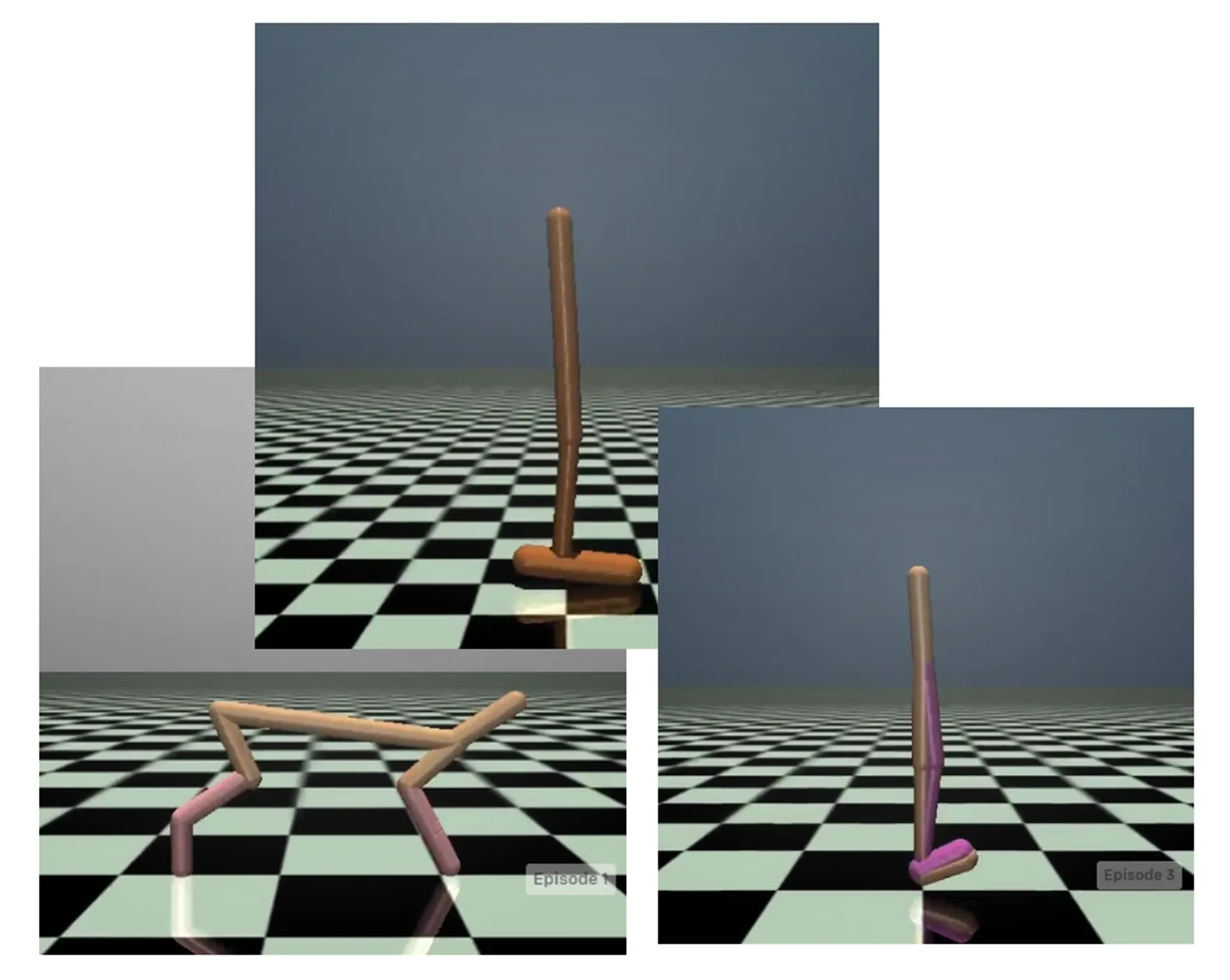
MuJoCo连续控制任务是在线强化学习算法的标准测试平台。我们从中选择了Halfcheetah-v3、Walker2d-v3和Hopper-v3三种常用于之前离线基准集的环境构建了离线强化学习任务。
git clone https://github.com/polixir/neorl.git cd neorl pip install -e . pip install -e .[mujoco] import neorl env = neorl.make("citylearn") data = env.get_dataset()